By Sumo Logic
クラウドを利用して仕事をする組織はますます増えています。どのようなクラウドモデルを採用するかは、企業のビジネスモデルによって異なります。クラウドサービスの最も一般的な導入モデルは、SaaS(Software-as-a-Service)、PaaS(Platform-as-a-Service)、IaaS(Infrastructure-as-a-Service)の3つです。
ここでは、これらのクラウドモデルの違いと、組織に適したモデルを選択する際に考慮すべき点について説明します。また、これらの導入モデルを管理する際に、Sumo Logic がどのように役立つかをご紹介します。
SaaS
SaaSとは
SaaS(Software as a Service)とは、インターネットを利用して、サードパーティのベンダーが管理するアプリケーションをユーザーに提供することです。
提供方法
SaaSは、サードパーティによりインターネットを介して、すべてのクライアントに直接に機能が提供されます。ソフトウェアのメンテナンスはサードパーティがリモートで行います。
SaaSのメリット
ベンダーがリモートでインストール、設定、メンテナンスを行うため、クライアントのIT部門は、事業に関わるより重要な問題に時間を割くことができます。これは時間の節約だけでなく、コストの節約にもつながります。
SaaSの特徴
SaaSアプリケーションは、インターネットを介してアクセスすることができます。これらのアプリケーションは集中管理され、リモートサーバにホストされています。必要なハードウェアとソフトウェアの設定は、ユーザーではなくベンダーが責任を持って行います。
SaaSを利用する理由
第一に、SaaSはソフトウェアを管理する時間がない企業、例えばスタートアップ企業にはメリットがあります。
第二に、SaaSの導入方法は、Webやモバイルからアクセスできるアプリケーションが必要な場合に非常に適しています。また、日常的に使用しないアプリケーションにもお勧めです。
最後に、SaaSはサブスクリプション型のため、短期間だけ特定のアプリケーションが必要な場合に適しています。
制限事項と懸念事項
SaaSの導入モデルを使用する際には、いくつかの制限や懸念事項があります。まず、ベンダーロックインが発生する可能性があります。SaaSアプリの習得は簡単かもしれませんが、他のSaaSアプリに移行する際には、データのポータビリティに大きなコストがかかることに注意してください。また、すべてのSaaSアプリがインテグレーションのためのオープンスタンダードに準拠しているわけではないため、相互運用性の低さにも注意が必要です。そのため、他のアプリと接続する際に問題が発生する可能性があります。
セキュリティについては、パブリッククラウドベースのSaaSアプリは、機密性の高いビジネスデータを転送する際のセキュリティが低く、セキュリティ、コンプライアンス、プライバシーの問題につながる可能性があります。
最後に、SaaSアプリは専門性の高いアプリであるため、万能なソリューションは存在しません。そのため、カスタマイズはオンプレミスのアプリに比べて困難です。
Sumo LogicとSaaSベンダー
Sumo Logicは、クラウド規模でアプリケーションを運用し、セキュリティを確保するためのリアルタイムSaaSプラットフォームです。ここでは機械学習が重要な役割を果たします。Salesforceのような他のSaaSプラットフォームと簡単にインテグレーションすることができます。
Sumo Logic Continuous Intelligenceソリューションを使用すると、Salesforceのパフォーマンスをリアルタイムで監視できるだけでなく、セキュリティ侵害の可能性を迅速に特定して修正することができます。これは他のSaaSアプリにも当てはまります。
SaaSの例
PaaS
PaaSとは
Platform as a Service(PaaS)は、開発者がカスタマイズしたアプリケーションを構築できるフレームワークを提供します。
提供方法
PaaSの提供方法はSaaSとほぼ同じです。インターネットでソフトウェア機能を提供する代わりに、PaaSはソフトウェアを作成するためのプラットフォームを提供します。PaaSでは、企業はミドルウェアと呼ばれるソフトウェアコンポーネントを使って、PaaSに組み込まれたアプリケーションを設計・作成することができます。
PaaSのメリット
PaaSを利用すると、アプリの開発、デプロイが簡単で低コストでできます。開発されたアプリは拡張性と可用性が高くなります。開発者はミドルウェアを気にすることなくアプリをカスタマイズすることができるため、開発スピードが速くなります。
PaaSの特徴
仮想化技術により、必要に応じてリソースを簡単にスケールアップ/ダウンすることができます。PaaSは基本的にアプリケーションの開発、テスト、デプロイメントを支援するサービス群です。複数のユーザーが同じ開発プラットフォームを介してアクセスでき、Webサービスやデータベースとのスムーズなインテグレーションが可能です。
PaaSを利用する理由
PaaSを使えば、開発のワークフローを効率化することができます。
PaaSは拡張性のあるカスタマイズされたアプリケーションのための素晴らしいプラットフォームを提供します。
PaaSを利用すれば、限られた予算の中でプラットフォームを持つことができ、コストを削減することができます。また、迅速なアプリ開発とデプロイも可能になります。
制限と懸念事項
SaaSと同様に、PaaSにも制限や懸念事項があります。組織はPaaSソリューション上で独自のアプリを実行することができますが、データはPaaSベンダーによって管理されているサードパーティのサーバ上にあります。このため、データのセキュリティやプライバシーのリスクが懸念されます。
ベンダーロックインの可能性があり、ベンダーがしっかりとした移行ポリシーを持っていない場合、PaaSソリューションを切り替えるのは難しいかもしれません。
PaaSソリューションがあなたの選択したフレームワークや言語と互換性がない場合、ランタイムの問題が発生する可能性があります。PaaSソリューションが動作する言語やフレームワークのバージョンにも注意してください。
また、レガシーシステムをお持ちの場合には、レガシーシステム用にカスタマイズできないPaaSソリューションもありますので、注意が必要です。
PaaSの例
Sumo LogicとPaaSベンダー
Microsoft Azure Cloud は、Sumo Logic との連携が可能な PaaS ソリューションの一例です。Azure MonitorやEvent Hubとのインテグレーションは簡単です。Sumo Logicは Azure Audit、Network Inspector、SQL、Active Directory などのコンテンツの可視性を高めることもできます。
IaaS
IaaSとは
IaaS(Infrastructure as a Service)とは、コンピュータやストレージ、ネットワークなどへのアクセスや監視が可能なコンピューティングリソースのことです。追加でハードウェアを購入する必要はありません。
クライアントはIaaSベンダーからハードウェアをリースします。
IaaSの提供方法
提供は仮想化されたクラウドサーバを介して行われます。ダッシュボードやAPIを利用して、クライアントがインフラ全体を完全にコントロールできるようにします。IaaSはクラウド上の「仮想データセンター」をアウトソースしたものです。
SaaSやPaaSとは異なり、IaaSのクライアントはアプリケーションやオペレーティングシステムなどを管理する責任があります。しかし、サーバやハードドライブなどはIaaSプロバイダーが管理します。
IaaSのメリット
IaaSは、ストレージ、ネットワーク、サーバ、処理能力をシンプルに配置した非常に柔軟性の高いクラウドコンピューティングモデルです。
IaaSのコストは様々ですが、基本的にはクライアントの利用量に依存します。クライアントはインフラを完全にコントロールすることができ、高いスケーラビリティから利益を得ることができます。
IaaSの特徴
IaaSの特徴は、リソースをサービスとして提供するハードウェアインフラをリースすることです。前述の通り、利用量に応じてコストが変動します。
複数のユーザーが1つのハードウェアで作業することができます。そのため、非常に柔軟で拡張性の高い導入モデルとなっています。
IaaSを利用する理由
スタートアップや小規模企業にとって、IaaSはハードウェアやソフトウェアを購入せずに開発が行える手段です。これにより、時間とコストを節約することができます。大企業や成長企業にとっては、現在のニーズに応じて特定のハードウェアやソフトウェアに切り替える必要があるため、IaaSはメリットがあります。
制限と懸念事項
SaaSやPaaSと同様に、IaaSにも一定の制限や懸念点があります。
IaaSベンダーとクライアントは仮想マシンを介して接続されており、セキュリティが危うくなる可能性があります。複数企業で環境を共有するマルチテナントの場合、IaaSベンダーはクライアントのみが割り当てられたIaaSソリューションにアクセスでき、他のクライアントはアクセスできないようにしなければなりません。
PaaSと同様に、IaaSにもレガシーシステム用にカスタマイズできない可能性があります。
顧客はデータのセキュリティ、バックアップ、事業継続の責任を負うことになります。これには十分なトレーニングが必要であり、費用と時間がかかります。
IaaSの例
Sumo LogicとIaaSベンダー
前述の通り、サードパーティ製のインフラ(IaaS)をリースする際には、セキュリティが課題となります。そこでSumo Logicは、IT組織に提供するセキュリティ分析ツールを作成しました。
- クラウドネットワークセキュリティの統合ビュー
- クライアントのプライベートクラウド、パブリッククラウド、ハイブリッドクラウドの監視ソリューション
あらゆるクラウドデリバリーシステム(SaaS、PaaS、IaaS)に対応するために、Sumo Logicはクライアント向けのソリューションを用意しています。
本記事は米国Sumo Logic社のサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。
" target="_blank">




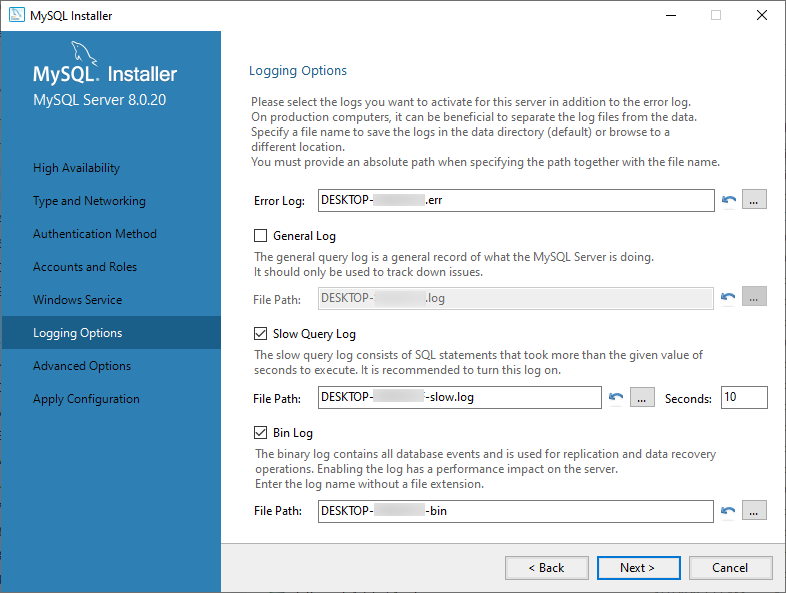
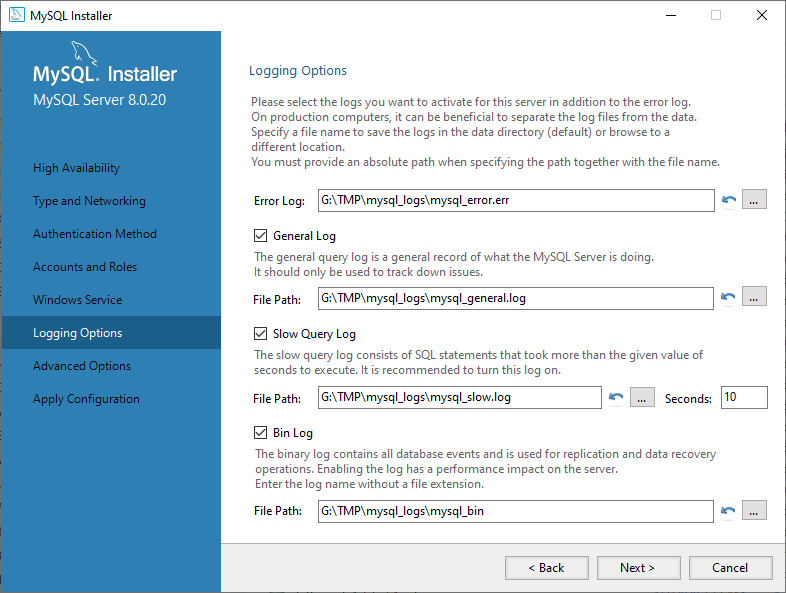 一般的なクエリ、低速クエリ、バイナリログはインストーラの GUI を通じて手動で有効/無効にできますが、エラーログはできません。また、各ログの名前とパスを手動で設定することもできます。
インストール後、ログの設定はユーザーが編集可能な C:¥ProgramData¥MySQL¥MySQL Server [バージョン]¥my.ini で管理されます。このファイルでログ名やパス、有効/無効を設定できます。
一般的なクエリ、低速クエリ、バイナリログはインストーラの GUI を通じて手動で有効/無効にできますが、エラーログはできません。また、各ログの名前とパスを手動で設定することもできます。
インストール後、ログの設定はユーザーが編集可能な C:¥ProgramData¥MySQL¥MySQL Server [バージョン]¥my.ini で管理されます。このファイルでログ名やパス、有効/無効を設定できます。


 LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトやアプリケーション用に作成されたフォルダがあります。
デフォルトのサーバログフォルダはW3SVC1です。追加のフォルダは「1」をより長い乱数に置き換えます。デフォルトでは、「formatDDMMYY.log」というファイル名でNCSA、Extended、あるいはIISのフォーマットで新しいアクセスログファイルが毎日作成されます。LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトまたはアプリケーション用に作成されたフォルダーがあります。
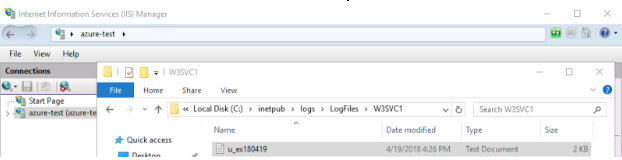
下はWebサイトとログフォルダとファイルの例です。
LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトやアプリケーション用に作成されたフォルダがあります。
デフォルトのサーバログフォルダはW3SVC1です。追加のフォルダは「1」をより長い乱数に置き換えます。デフォルトでは、「formatDDMMYY.log」というファイル名でNCSA、Extended、あるいはIISのフォーマットで新しいアクセスログファイルが毎日作成されます。LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトまたはアプリケーション用に作成されたフォルダーがあります。
下はWebサイトとログフォルダとファイルの例です。

 ほとんどのディストリビューションのパッケージ版Apache HTTPを使用する場合、ファイルは/var/log/httpdにあります。デフォルト設定を使用してソースからコンパイルする場合、ログファイルは$PREFIX/logsにあります。$PREFIXはコンパイル中に設定でき、デフォルトの場所は/usr/local/apache2です。
ほとんどのディストリビューションのパッケージ版Apache HTTPを使用する場合、ファイルは/var/log/httpdにあります。デフォルト設定を使用してソースからコンパイルする場合、ログファイルは$PREFIX/logsにあります。$PREFIXはコンパイル中に設定でき、デフォルトの場所は/usr/local/apache2です。
 IIS形式は、3つの形式の中で最も情報が多く、時間ベースやサイズベースなど、複数の種類のファイルローテーションをサポートしています。
IIS形式は、3つの形式の中で最も情報が多く、時間ベースやサイズベースなど、複数の種類のファイルローテーションをサポートしています。
 NCSAはApache HTTP、NGINXや他のいくつかのWebサーバで使用される形式です。他の2つのテキストオプションと比較して、データのバランスが良い構文を持っています。
NCSAはApache HTTP、NGINXや他のいくつかのWebサーバで使用される形式です。他の2つのテキストオプションと比較して、データのバランスが良い構文を持っています。