
Sumo Logicでsyslogデータを監視する方法
- On 2019年9月27日


- カテゴリー
スポットライト
- 継続的インテリジェンスレポート
この記事を読んでいる方は、おそらく1980年代から使用されているロギングツールであるsyslogに精通していることでしょう。ほとんどのLinuxベースのオペレーティングシステムに存在するデーモンです。
デフォルトでは、Linuxシステムのsyslog(およびrsyslogなどの派生アプリ)を使用して、ログをsyslogサーバや監視プラットフォームに転送して、さらに分析を行うことができます。これは便利ですが、syslogを最大限に活用するには、ログデータを分析できるようにする必要もあります。
そこで、ここではローカルのシステムログを取得し、Sumo Logicコレクターを使用してSumo Logicに転送するプロセスを説明します。
また、syslogやrsyslogデーモンを使用して、サーバからログを送信する方法も示します。
はじめに
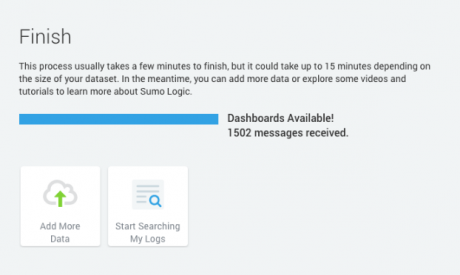
ログをSumo Logicにストリーミングできるようにするには、まずパッケージにサインアップする必要があります。有料のオプションもありますが、Sumo Logicのテストとして、ストリーミングするログの量を少なくし、1日最大500Mバイトまでならば無料で使えるオプションがあります。サインアップすると、次のようなページが表示され、ログファイルをアップロードするか、ストリーミングログにすぐにジャンプするかを選択します。ここでは後者のオプションを選択します。
ストリーミングログ
「Set Up Streaming Data」ボタンをクリックすると、Linux、Windows、あるいはMacからAWS環境をすぐに開始できるオプションが表示されます。
コレクターのインストール
今回はLinuxを選択します。これにより、次のような簡単なコマンドでSumo Logicコレクターをデプロイできます。
sudo wget 'https://collectors.de.sumologic.com/rest/download/linux/64' -O SumoCollector.sh && sudo chmod + x SumoCollector.sh && sudo ./SumoCollector.sh -q -Vsumo.token_and_url=<unique_token>
コマンドを実行すると、コレクターがインストールされ、Sumo Logicに自動的に登録されます。この時点で、「Continue」をクリックできるようになります。
ソースの構成
次に、データのソース情報を設定します。まず、ソースカテゴリーを設定します。これは、収集時に各メトリックの時系列に追加されるメタデータタグです。希望する任意の名前を設定できます。これを使用して、将来このソースからのメトリックを見つけることができます。
プロセスのこの時点で、データを収集するログファイルを設定することもできます。デフォルトでは、/var/log/secure*と/var/log/messages*がスクレイピング用に選択されています。もちろん、収集したい他のログファイルを追加できます。例えば、実行中にアプリが生成するログファイルです。
最後に、ログファイルのタイムゾーンを使用するか、無視して別のタイムゾーンを使用するかを選択できます。これで、「Continue」をクリックする準備ができました。ログのサイズが大きい場合には、Collectorが設定とデータを追加する間にコーヒーが1杯飲めるかもしれません。
完了すると次のように表示されます。
ログを検索する
では、楽しい作業に移りましょう。ログを表示して、情報を検索します。「Linux System」という名前のページの上部にあるサンプル検索オプションを使用すると、サーバからストリーミングされたログを表示できます。「sumologic」という名前のログも含めるように検索クエリを修正しました。これがその結果です。
ホスト名、データ取得元のログファイル名、セットアップ中に設定した「linux/system」というカテゴリーが表示されます。
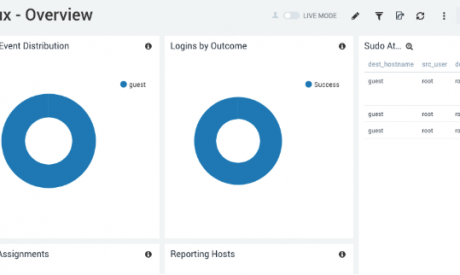
また、ログイン時に一般的な情報を表示できる便利なダッシュボードもあります。もちろん、ログの情報に基づいてこれを変更し、新しいグラフを追加できます。これは、アプリケーションのHTTPエラーの詳細など、さまざまな機能に使用できます。たとえばメールサーバならば、バウンスや拒否されたメールの数を表示できます。
Syslogソースの追加
Syslogソースを追加するには、Sumo Logicコントロールパネルで新しいソースを設定します。これを行うには、「Manage Data」→「Collection」→「Collection」に移動します。次に、「Add」→「Add Source」→「Syslog」をクリックします。ここでは、プロトコル(TCPまたはUDP)とポート番号とともにsyslog名を指定します。この記事では、ポート1514でUDPを選択しました。linux/syslogのソースカテゴリーを使用することにしました。ここで「Save」をクリックします。コレクターがサーバのUDPポート1514をリッスンしているサービスが表示されます。
この時点で、コレクターの新しいリスナーにログを送信するようsyslogを設定する準備が整いました。設定にはsyslogまたはrsyslogの設定ファイルを編集します。この場合、後者は/etc/rsyslog.confです。このログファイルの最後に、コメントアウトされた行があります。
# remote host is: name/ip:port, e.g. 192.168.0.1:514, port optional
#*.* @@remote-host:514
# ### end of the forwarding rule ###
この行のコメントを外し、IPアドレスとポートを変更して、rsyslogが保持するすべてのログ(*.*)を新しいリスナーに送信します。
# remote host is: name/ip:port, e.g. 192.168.0.1:514, port optional
*.* @127.0.0.1:1514
# ### end of the forwarding rule ###
ログ送信にTCPではなくUDPを使用するようにrsyslogに指示する「@」をIPアドレスの先頭に付加してください。
コレクターに対してこのメソッドを単独で使用する理由
ここで説明したアプローチを採用する理由は次の通りです。
組織内の中央syslogサーバにコレクターをセットアップし、すべてのログをSumo Logicに転送することができます。このアプローチの利点は、すべてのサーバに個別にコレクターをインストールする必要がないため、非常に多くのソースからのトラフィックを許可するために企業のファイアウォールを開ける必要がないことです。
結論
Sumo Logicは、大規模な組織に存在する可能性のある制限を回避するために、リスナーを独自の環境に拡張できる包括的なクラウドソリューションを提供します。これにインターフェイス、合理化されたセットアッププロセス、ダッシュボードを組み合わせることで、非常に競争力のあるソリューションとなり、ログを積極的に監視し、お客様に影響を与える前に問題を発見できます。
キース・ロジャース
キース・ロジャースは、10年以上の経験を持つITプロフェッショナルで、現在は英国の大手放送会社で働いています。彼の長年にわたるコンピューティングへの情熱は、いくつもの業務外の活動をうながし、彼の知識を深め関心を高めることにつながりました。
キースは長年Linux上でApache、MySQL、PHPを使用して完全なWebスタックを構築し、高可用性に適したより複雑な負荷分散と冗長ソリューションを作成してきました。過去2、3年、彼はAWSやAzureが提供する新しいクラウドベースのインフラストラクチャを使用して、同様の目標を達成しています。
" target="_blank">
0 Comments