ログを知る〜IISとApache、NGINXのログ
- On 2019年10月16日
カテゴリー DevOpsとIT運用 スポットライト DevSecOpsの完全な可視性 IoTボットネットの脅威を軽減するためのセキュリティ戦略 AWS CloudTrailログを読み取り、検索、分析する方法 今日のWebサーバエコシステムには、インターネットインフォメーションサービス(IIS)、Apache、NGINXの3つの大きなプレーヤーがいます。そのうち2つ(Apacheと割合は低いがNGINX)だけがクロスプラットフォームですが、どれもサポートすることを求められる可能性があるので、これらの3つのサーバすべてと連携できることがますます重要になります。 そのため、IIS、Apache、NGINXログの微妙な違いを理解することが重要です。完璧な世界では、これらのサーバはすべて同じログ形式とログデータを持ちますが、実際にはそうではありません。 この記事では、IIS、Apache、NGINXのログの違いと、DevOpsエンジニアが各サーバのログを操作するために知る必要がある重要な情報について説明します。 IIS、Apache、NGINX、の歴史とログ IISとApacheの戦いは20年間続いています。最初は、人々はしっかりと一方の側にいて、それは会社がWindowsのみであるか、UNIX/Linuxシステムが利用可能かによってしばしば決定されました。これらのシステムには、Webサイトにサービスを提供できることを除いて、共通点はありません。ログファイルは、実行されたオペレーティングシステムと同じくらい異なっていました。時が経ち2000年代になると、仮想化とLinuxが主流になってきたため、組織は一般的にApache HTTPとIISの両方のインストールを行いました。 同じ時期に、NGINXはApache HTTPの直接の競争相手になりました。NGINXは、Apache HTTPを凌ぐように設計されましたが、既存のログ管理ソリューションを再利用して、管理者がApacheからNGINXに簡単に移行できるようなログ形式を使用することで、Apache周りに構築されたエコシステムを活用しました。 Apache、NGINX、IISのログはどこに? IIS IISでWindows 2008とVistaでリリースされたバージョン7でログファイルのデフォルトの場所が変更されました。IIS 6以前はログは%SystemRoot%System32LogFilesの下にありましたが、IIS 7では%SystemDrive%inetpublogs LogFilesに移動しました。 LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトやアプリケーション用に作成されたフォルダがあります。 デフォルトのサーバログフォルダはW3SVC1です。追加のフォルダは「1」をより長い乱数に置き換えます。デフォルトでは、「formatDDMMYY.log」というファイル名でNCSA、Extended、あるいはIISのフォーマットで新しいアクセスログファイルが毎日作成されます。LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトまたはアプリケーション用に作成されたフォルダーがあります。 下はWebサイトとログフォルダとファイルの例です。 Apache HTTP Apache HTTPのログはパッケージからインストールされた場合、UNIXやLinuxベースのサーバでは/var/log以下にあります。Windowsでは、ソースからコンパイルする場合、設定ファイルやバイナリと同じディレクトリの下にあります。 *デフォルトのファイル名はaccess_logおよびerror_logですが、例外もあります。 ほとんどのディストリビューションのパッケージ版Apache HTTPを使用する場合、ファイルは/var/log/httpdにあります。デフォルト設定を使用してソースからコンパイルする場合、ログファイルは$PREFIX/logsにあります。$PREFIXはコンパイル中に設定でき、デフォルトの場所は/usr/local/apache2です。 NGINX NGINXはApacheよりも一貫性が高く、すべてのディストリビューションで、/var/log/nginxのベースディレクトリにerror.logとaccess.logのファイル名を使用するパッケージを使用しています。 ソースからコンパイルする場合、またはWindows上で実行する場合、デフォルトの場所はベースインストールディレクトリの下のログディレクトリで、ファイル名はaccess_logとerror_logです。 IISアクセスロギング 前述のように、IISにはログファイルを保存できる複数の形式があります。そのうちの1つは、データベースにも書き込むことができるバイナリ形式ですが、ログのインフラが複雑になるので理想的とはいえません。 テキストベースの形式では、W3C拡張、IIS、NCSAという3つのオプションがあります。 W3C拡張形式は、日付ではなく時刻のみを持つため、デフォルトのDailyのように、実際には時間ベースのファイルローテーションでのみ機能します。 IIS形式は、3つの形式の中で最も情報が多く、時間ベースやサイズベースなど、複数の種類のファイルローテーションをサポートしています。 NCSAはApache HTTP、NGINXや他のいくつかのWebサーバで使用される形式です。他の2つのテキストオプションと比較して、データのバランスが良い構文を持っています。 Apache対NGINXアクセスロギング ApacheとNGINXは両方とも、デフォルトでNCSAフォーマットのアクセスロギングを使用します。 ApacheとNGINXの両方には、アクセスログのデータをカスタマイズして、情報を増やしたり減らしたりする機能があります。一般的に使用されるこの形式は、コンバインドと呼ばれます。 コンバインドは、HTTP_RefererとUser_Agentと呼ばれる2つのデータフィールドが追加されたNCSAフォーマットに基づいています。この2つのフィールドは、ログをWeb分析やキャンペーントラッキングなどのマーケティング活動の基盤として使用する場合に非常に役立ちます。ただし、ほとんどの組織は、マーケティング活動のためにより堅牢なJavaScriptベースの追跡ソリューション(Googleアナリティクスなど)に移行したため、コンバインドは使用しなくなりました。 エラーログ IISとNGINXとApacheのエラーログは、日付、時刻、エラーコード(利用可能な場合)とstderrの出力の形式で、いたって分かりやすくなっています。エラーはファイル内の複数の行にまたがることができるため、ログを正しく理解して処理できる適切なログ収集エンジン(Sumo Logicなど)を用意すると役立ちます。 結論 IIS、Apache、NGINXのログは多くの点で異なります。幸いなことに、Sumo Logicのような最新のログ統合サービスを活用することで、アクティビティの追跡と問題解決の両方について、すべてのプラットフォームで統一されたビューを簡単に取得できます。さらに、アクセスログにNCSAフォーマットを使用するようにIISを構成できることにより、これらの集中ログリポジトリの検索と特定のデータのマイニングが可能になり、ログ統合ツールを使用した日常作業が可能になります。 ヴィンス・パワー Vince Powerはソリューションアーキテクトであり、クラウドの採用とオープンソースベースのテクノロジーの実装にフォーカスしています。彼は、コアコンピューティングとネットワーク(IaaS)、アイデンティティとアクセス管理(IAM)、アプリケーションプラットフォーム(PaaS)、継続的デリバリーなどの幅広い経験を持っています。
Read More
- カテゴリー
スポットライト
今日のWebサーバエコシステムには、インターネットインフォメーションサービス(IIS)、Apache、NGINXの3つの大きなプレーヤーがいます。そのうち2つ(Apacheと割合は低いがNGINX)だけがクロスプラットフォームですが、どれもサポートすることを求められる可能性があるので、これらの3つのサーバすべてと連携できることがますます重要になります。 そのため、IIS、Apache、NGINXログの微妙な違いを理解することが重要です。完璧な世界では、これらのサーバはすべて同じログ形式とログデータを持ちますが、実際にはそうではありません。 この記事では、IIS、Apache、NGINXのログの違いと、DevOpsエンジニアが各サーバのログを操作するために知る必要がある重要な情報について説明します。IIS、Apache、NGINX、の歴史とログ
IISとApacheの戦いは20年間続いています。最初は、人々はしっかりと一方の側にいて、それは会社がWindowsのみであるか、UNIX/Linuxシステムが利用可能かによってしばしば決定されました。これらのシステムには、Webサイトにサービスを提供できることを除いて、共通点はありません。ログファイルは、実行されたオペレーティングシステムと同じくらい異なっていました。時が経ち2000年代になると、仮想化とLinuxが主流になってきたため、組織は一般的にApache HTTPとIISの両方のインストールを行いました。 同じ時期に、NGINXはApache HTTPの直接の競争相手になりました。NGINXは、Apache HTTPを凌ぐように設計されましたが、既存のログ管理ソリューションを再利用して、管理者がApacheからNGINXに簡単に移行できるようなログ形式を使用することで、Apache周りに構築されたエコシステムを活用しました。Apache、NGINX、IISのログはどこに? IIS
IISでWindows 2008とVistaでリリースされたバージョン7でログファイルのデフォルトの場所が変更されました。IIS 6以前はログは%SystemRoot%System32LogFilesの下にありましたが、IIS 7では%SystemDrive%inetpublogs LogFilesに移動しました。 LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトやアプリケーション用に作成されたフォルダがあります。
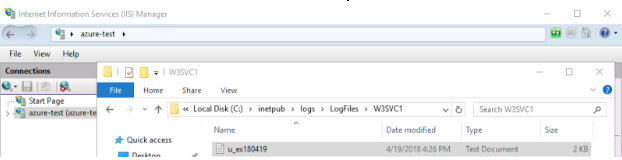
デフォルトのサーバログフォルダはW3SVC1です。追加のフォルダは「1」をより長い乱数に置き換えます。デフォルトでは、「formatDDMMYY.log」というファイル名でNCSA、Extended、あるいはIISのフォーマットで新しいアクセスログファイルが毎日作成されます。LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトまたはアプリケーション用に作成されたフォルダーがあります。
下はWebサイトとログフォルダとファイルの例です。
LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトやアプリケーション用に作成されたフォルダがあります。
デフォルトのサーバログフォルダはW3SVC1です。追加のフォルダは「1」をより長い乱数に置き換えます。デフォルトでは、「formatDDMMYY.log」というファイル名でNCSA、Extended、あるいはIISのフォーマットで新しいアクセスログファイルが毎日作成されます。LogFilesディレクトリ内には、IISマネージャー管理コンソールでセットアップされたすべてのWebサイトまたはアプリケーション用に作成されたフォルダーがあります。
下はWebサイトとログフォルダとファイルの例です。
Apache HTTP
Apache HTTPのログはパッケージからインストールされた場合、UNIXやLinuxベースのサーバでは/var/log以下にあります。Windowsでは、ソースからコンパイルする場合、設定ファイルやバイナリと同じディレクトリの下にあります。 *デフォルトのファイル名はaccess_logおよびerror_logですが、例外もあります。
 ほとんどのディストリビューションのパッケージ版Apache HTTPを使用する場合、ファイルは/var/log/httpdにあります。デフォルト設定を使用してソースからコンパイルする場合、ログファイルは$PREFIX/logsにあります。$PREFIXはコンパイル中に設定でき、デフォルトの場所は/usr/local/apache2です。
ほとんどのディストリビューションのパッケージ版Apache HTTPを使用する場合、ファイルは/var/log/httpdにあります。デフォルト設定を使用してソースからコンパイルする場合、ログファイルは$PREFIX/logsにあります。$PREFIXはコンパイル中に設定でき、デフォルトの場所は/usr/local/apache2です。
NGINX
NGINXはApacheよりも一貫性が高く、すべてのディストリビューションで、/var/log/nginxのベースディレクトリにerror.logとaccess.logのファイル名を使用するパッケージを使用しています。 ソースからコンパイルする場合、またはWindows上で実行する場合、デフォルトの場所はベースインストールディレクトリの下のログディレクトリで、ファイル名はaccess_logとerror_logです。IISアクセスロギング
前述のように、IISにはログファイルを保存できる複数の形式があります。そのうちの1つは、データベースにも書き込むことができるバイナリ形式ですが、ログのインフラが複雑になるので理想的とはいえません。 テキストベースの形式では、W3C拡張、IIS、NCSAという3つのオプションがあります。 W3C拡張形式は、日付ではなく時刻のみを持つため、デフォルトのDailyのように、実際には時間ベースのファイルローテーションでのみ機能します。 IIS形式は、3つの形式の中で最も情報が多く、時間ベースやサイズベースなど、複数の種類のファイルローテーションをサポートしています。
IIS形式は、3つの形式の中で最も情報が多く、時間ベースやサイズベースなど、複数の種類のファイルローテーションをサポートしています。
 NCSAはApache HTTP、NGINXや他のいくつかのWebサーバで使用される形式です。他の2つのテキストオプションと比較して、データのバランスが良い構文を持っています。
NCSAはApache HTTP、NGINXや他のいくつかのWebサーバで使用される形式です。他の2つのテキストオプションと比較して、データのバランスが良い構文を持っています。

Apache対NGINXアクセスロギング
ApacheとNGINXは両方とも、デフォルトでNCSAフォーマットのアクセスロギングを使用します。 ApacheとNGINXの両方には、アクセスログのデータをカスタマイズして、情報を増やしたり減らしたりする機能があります。一般的に使用されるこの形式は、コンバインドと呼ばれます。 コンバインドは、HTTP_RefererとUser_Agentと呼ばれる2つのデータフィールドが追加されたNCSAフォーマットに基づいています。この2つのフィールドは、ログをWeb分析やキャンペーントラッキングなどのマーケティング活動の基盤として使用する場合に非常に役立ちます。ただし、ほとんどの組織は、マーケティング活動のためにより堅牢なJavaScriptベースの追跡ソリューション(Googleアナリティクスなど)に移行したため、コンバインドは使用しなくなりました。エラーログ
IISとNGINXとApacheのエラーログは、日付、時刻、エラーコード(利用可能な場合)とstderrの出力の形式で、いたって分かりやすくなっています。エラーはファイル内の複数の行にまたがることができるため、ログを正しく理解して処理できる適切なログ収集エンジン(Sumo Logicなど)を用意すると役立ちます。結論
IIS、Apache、NGINXのログは多くの点で異なります。幸いなことに、Sumo Logicのような最新のログ統合サービスを活用することで、アクティビティの追跡と問題解決の両方について、すべてのプラットフォームで統一されたビューを簡単に取得できます。さらに、アクセスログにNCSAフォーマットを使用するようにIISを構成できることにより、これらの集中ログリポジトリの検索と特定のデータのマイニングが可能になり、ログ統合ツールを使用した日常作業が可能になります。
ヴィンス・パワー
Vince Powerはソリューションアーキテクトであり、クラウドの採用とオープンソースベースのテクノロジーの実装にフォーカスしています。彼は、コアコンピューティングとネットワーク(IaaS)、アイデンティティとアクセス管理(IAM)、アプリケーションプラットフォーム(PaaS)、継続的デリバリーなどの幅広い経験を持っています。" target="_blank">